Note
Click here to download the full example code
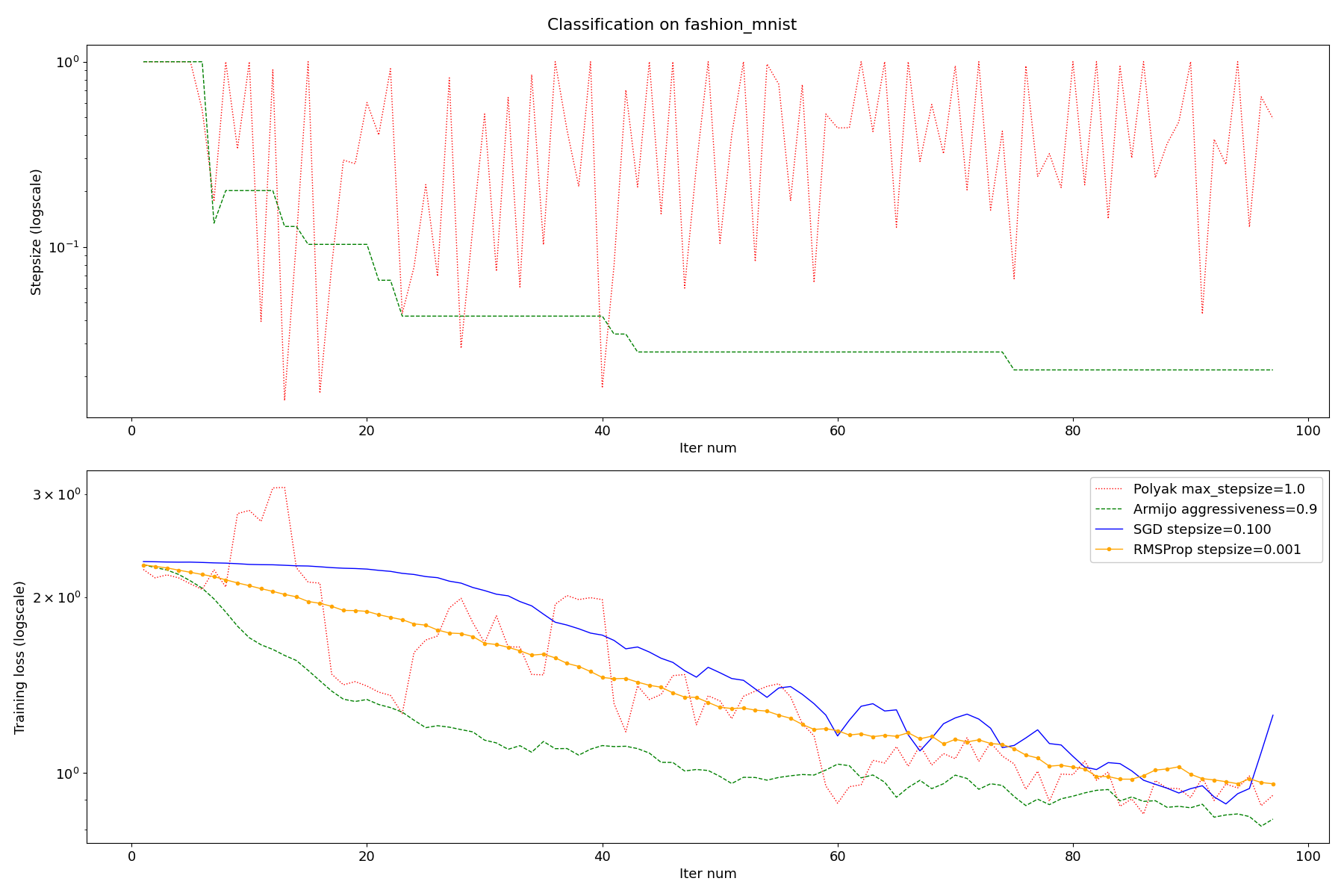
Comparison of different SGD algorithms.
The purpose of this example is to illustrate the power of adaptive stepsize algorithms.
We chose a classification task with classes that are easily separable and no regularization (interpolating regime).
We compare:
SGD with Polyak stepsize (theoretical guarantees require interpolation)
SGD with Armijo line search (theoretical guarantees require interpolation)
SGD with constant stepsize
RMSprop
The reported training loss is an estimation of the true training loss based
on the current minibatch.
This experiment was conducted without momentum, with popular default values for learning rate.
/Users/mblondel/envs/work/lib/python3.9/site-packages/flax/struct.py:132: FutureWarning: jax.tree_util.register_keypaths is deprecated, and will be removed in a future release. Please use `register_pytree_with_keys()` instead.
jax.tree_util.register_keypaths(data_clz, keypaths)
/Users/mblondel/envs/work/lib/python3.9/site-packages/flax/struct.py:132: FutureWarning: jax.tree_util.register_keypaths is deprecated, and will be removed in a future release. Please use `register_pytree_with_keys()` instead.
jax.tree_util.register_keypaths(data_clz, keypaths)
[Polyak SGD] ( 0), error=0.272, loss=2.301, stepsize=1.000000
[Polyak SGD] ( 20), error=1.919, loss=1.482, stepsize=0.402169
[Polyak SGD] ( 40), error=4.585, loss=1.666, stepsize=0.079269
[Polyak SGD] ( 60), error=1.422, loss=0.891, stepsize=0.440547
[Polyak SGD] ( 80), error=2.356, loss=1.200, stepsize=0.216168
[Polyak SGD] ( 100), error=3.512, loss=1.183, stepsize=0.095881
101 iterations of Polyak SGD took 15.15s
[Armijo SGD] ( 0), error=0.227, loss=2.313, stepsize=1.000000
[Armijo SGD] ( 20), error=2.221, loss=1.331, stepsize=0.065971
[Armijo SGD] ( 40), error=2.062, loss=1.080, stepsize=0.033777
[Armijo SGD] ( 60), error=3.499, loss=1.059, stepsize=0.027022
[Armijo SGD] ( 80), error=1.456, loss=0.863, stepsize=0.021617
[Armijo SGD] ( 100), error=1.689, loss=0.819, stepsize=0.021617
101 iterations of Armijo SGD took 15.80s
[RMSProp] ( 0), error=0.223, loss=2.299
[RMSProp] ( 20), error=0.869, loss=1.913
[RMSProp] ( 40), error=1.151, loss=1.453
[RMSProp] ( 60), error=1.115, loss=1.211
[RMSProp] ( 80), error=1.627, loss=1.088
[RMSProp] ( 100), error=1.581, loss=1.002
101 iterations of RMSProp took 13.23s
[SGD] ( 0), error=0.190, loss=2.306
[SGD] ( 20), error=0.384, loss=2.236
[SGD] ( 40), error=2.765, loss=1.878
[SGD] ( 60), error=1.222, loss=1.092
[SGD] ( 80), error=1.637, loss=1.146
[SGD] ( 100), error=4.392, loss=1.671
101 iterations of SGD took 12.89s
from absl import flags
import logging
import sys
from timeit import default_timer as timer
import jax
import jax.numpy as jnp
from jaxopt import loss
from jaxopt import ArmijoSGD
from jaxopt import PolyakSGD
from jaxopt import OptaxSolver
from jaxopt.tree_util import tree_l2_norm, tree_sub
import optax
from flax import linen as nn
import numpy as onp
import matplotlib.pyplot as plt
from scipy.signal import convolve
import tensorflow_datasets as tfds
import tensorflow as tf
dataset_names = [
"mnist", "kmnist", "emnist", "fashion_mnist", "cifar10", "cifar100"
]
flags.DEFINE_float("rmsprop_stepsize", 1e-3, "RMSProp stepsize")
flags.DEFINE_float("gd_stepsize", 1e-1, "Gradient descent stepsize")
flags.DEFINE_float("aggressiveness", 0.9, "Aggressiveness of line search in armijo-sgd.")
flags.DEFINE_float("max_stepsize", 1.0, "Maximum step size (used in polyak-sgd, armijo-sgd).")
flags.DEFINE_integer("maxiter", 100, "Maximum number of iterations.")
flags.DEFINE_integer("batch_size", 128, "Batch-size.")
flags.DEFINE_integer("net_width", 4, "Width mutiplicator of network.")
flags.DEFINE_enum("dataset", "fashion_mnist", dataset_names, "Dataset to train on.")
jax.config.update("jax_platform_name", "cpu")
plt.rcParams.update({'font.size': 13})
# Load dataset.
def load_dataset(dataset, batch_size):
"""Loads the dataset as a generator of batches."""
train_ds, ds_info = tfds.load(f"{dataset}:3.*.*", split="train",
as_supervised=True, with_info=True)
train_ds = train_ds.repeat()
train_ds = train_ds.shuffle(10 * batch_size, seed=0)
train_ds = train_ds.batch(batch_size)
return tfds.as_numpy(train_ds), ds_info
# Define NN architecture.
class CNN(nn.Module):
"""A simple CNN model."""
num_classes: int
net_width: int
@nn.compact
def __call__(self, x):
x = nn.Conv(features=self.net_width, kernel_size=(3, 3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
x = nn.Conv(features=self.net_width*2, kernel_size=(3, 3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
x = x.reshape((x.shape[0], -1)) # flatten
x = nn.Dense(features=self.net_width*4)(x)
x = nn.relu(x)
x = nn.Dense(features=self.num_classes)(x)
return x
def main(argv):
# manual flags parsing to avoid conflicts between absl.app.run and sphinx-gallery
flags.FLAGS(argv)
FLAGS = flags.FLAGS
# Hide any GPUs from TensorFlow. Otherwise TF might reserve memory and make
# it unavailable to JAX.
tf.config.experimental.set_visible_devices([], 'GPU')
train_ds, ds_info = load_dataset(FLAGS.dataset, FLAGS.batch_size)
# Initialize parameters.
input_shape = (1,) + ds_info.features["image"].shape
rng = jax.random.PRNGKey(0)
num_classes = ds_info.features["label"].num_classes
net = CNN(num_classes, FLAGS.net_width)
logistic_loss = jax.vmap(loss.multiclass_logistic_loss)
def loss_fun(params, data):
"""Compute the loss of the network."""
inputs, labels = data
x = inputs.astype(jnp.float32) / 255.
logits = net.apply({"params": params}, x)
loss_value = jnp.mean(logistic_loss(labels, logits))
return loss_value
def run_all(opt, name):
"""Train the NN on dataset with ``opt``."""
# Use same starting hyper-parameters for fair evaluation.
params = net.init(rng, jnp.zeros(input_shape))["params"]
# Use same batch order for fair evaluation
ds_iterator = iter(train_ds)
state = opt.init_state(params, data=next(ds_iterator))
@jax.jit
def jitted_update(params, state, batch):
return opt.update(params, state, batch)
value_and_grad_loss = jax.value_and_grad(loss_fun)
errors, steps, losses = [], [], []
start = timer()
for iter_num, batch in zip(range(opt.maxiter+1), ds_iterator):
loss, _ = value_and_grad_loss(params, data=batch)
params, state = jitted_update(params, state, batch)
if "Armijo" in name or "Polyak" in name:
steps.append(state.stepsize)
errors.append(state.error)
losses.append(loss)
if iter_num % 20 == 0:
if "Armijo" in name or "Polyak" in name:
print(f"[{name}] ({iter_num:4d}), error={errors[-1]:.3f}, loss={losses[-1]:.3f}, stepsize={steps[-1]:.6f}")
else:
print(f"[{name}] ({iter_num:4d}), error={errors[-1]:.3f}, loss={losses[-1]:.3f}")
duration = timer() - start
print(f"{opt.maxiter+1} iterations of {name} took {duration:.2f}s\n")
losses = convolve(losses, onp.ones(5) / 5, mode='valid', method='direct') # smooth the curve
return errors[:len(losses)], steps[:len(losses)], losses
polyak = PolyakSGD(fun=loss_fun, max_stepsize=FLAGS.max_stepsize, maxiter=FLAGS.maxiter)
armijo = ArmijoSGD(fun=loss_fun, aggressiveness=FLAGS.aggressiveness, reset_option='goldstein',
max_stepsize=FLAGS.max_stepsize, maxls=20, maxiter=FLAGS.maxiter)
rmsprop = OptaxSolver(fun=loss_fun, maxiter=FLAGS.maxiter,
opt=optax.rmsprop(learning_rate=FLAGS.rmsprop_stepsize))
gd = OptaxSolver(fun=loss_fun, maxiter=FLAGS.maxiter,
opt=optax.sgd(learning_rate=FLAGS.gd_stepsize, nesterov=False))
errors_data, losses_data, stepsize_data = [], [], []
for opt, name in zip([polyak, armijo, rmsprop, gd], ["Polyak SGD", "Armijo SGD", "RMSProp", "SGD"]):
errors, steps, losses = run_all(opt, name)
errors_data.append(errors)
losses_data.append(losses)
stepsize_data.append(steps)
fig = plt.figure(figsize=(18,12))
fig.suptitle(f'Classification on {FLAGS.dataset}')
spec = fig.add_gridspec(ncols=2, nrows=2)
spec_slices = [spec[0,:], spec[1:,:]]
datas = stepsize_data, losses_data
names = ['Stepsize', 'Training loss']
for spec_slice, single_data, name in zip(spec_slices, datas, names):
polyak_data, armijo_data, rmsprop_data, gd_data = single_data
ax = fig.add_subplot(spec_slice)
ax.set_xlabel("Iter num")
ax.set_ylabel(f"{name} (logscale)")
iter_nums = jnp.arange(1, len(polyak_data)+1)
ax.plot(iter_nums, polyak_data, ':', c='red', linewidth=1., label=f'Polyak max_stepsize={FLAGS.max_stepsize}')
ax.plot(iter_nums, armijo_data, '--', c='green', linewidth=1., label=f'Armijo aggressiveness={FLAGS.aggressiveness}')
if name != 'Stepsize':
ax.plot(iter_nums, gd_data, '-', c='blue', linewidth=1., label=f'SGD stepsize={FLAGS.gd_stepsize:.3f}')
ax.plot(iter_nums, rmsprop_data, '.-', c='orange', linewidth=1., label=f'RMSProp stepsize={FLAGS.rmsprop_stepsize:.3f}')
ax.set_yscale('log')
leg = ax.legend(loc='upper right', framealpha=1.)
spec.tight_layout(fig)
plt.show()
if __name__ == "__main__":
main(sys.argv)
Total running time of the script: ( 1 minutes 1.032 seconds)